使用vLLM部署DeepSeek R1-Distill-Qwen-32B (Linux)
环境准备
首先,我们需要准备Python环境和必要的依赖:
- 创建并激活conda环境:
conda create -n vllm python=3.10
conda activate vllm
- 安装CUDA工具包(autodl容器中已经有了)
- 安装vLLM和ModelScope:
pip install vllm modelscope
下载模型
DeepSeek R1-Distill-Qwen-32B模型可以从ModelScope下载。使用以下命令:
# 使用modelscope下载
python -c "from modelscope.hub.snapshot_download import snapshot_download; snapshot_download('tclf90/deepseek-r1-distill-qwen-32b-gptq-int4', local_dir='/root/autodl-tmp/models/deepseek-r1-distill-qwen-32b')"
如果想用满血(不在本教程教学范围内),可使用huggingface下载int4满血(670b)版本:
python -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id='OPEA/DeepSeek-R1-int4-sym-gguf-q4-0-inc', local_dir='/root/autodl-tmp/Deepseek-R1-int4-sym-gguf-q4-0-inc', cache_dir=None, revision='main', ignore_patterns=['*.git'], local_files_only=False)"
启动服务
使用vLLM启动服务,注意调整参数以适应你的硬件配置:
因为autodl只开放6006端口,所以要服务要开到6006端口
vllm serve /root/autodl-tmp/models --dtype auto --api-key 132455 --trust-remote-code --max-model-len 8192 --gpu_memory_utilization 1 --port 6006
参数说明:
- --model: 模型路径
- --dtype auto: 自动选择最适合的数据类型
- --api-key: API密钥,这里使用132455
- --trust-remote-code: 信任模型代码
- --max-model-len: 最大上下文长度(这里32g内存可以调到22k)
- --gpu-memory-utilization: GPU显存使用率,根据显卡情况调整
- --port: 服务端口号
测试接口
可以使用curl命令测试API:
curl http://127.0.0.1:6006/v1/completions -H "Content-Type: application/json" -H "Authorization: Bearer 132455" -d '{"model": "/root/autodl-tmp/models", "prompt": "Write a hello world program in Python."}'
在笔记本/另一个服务器上连接使用
点击自定义服务

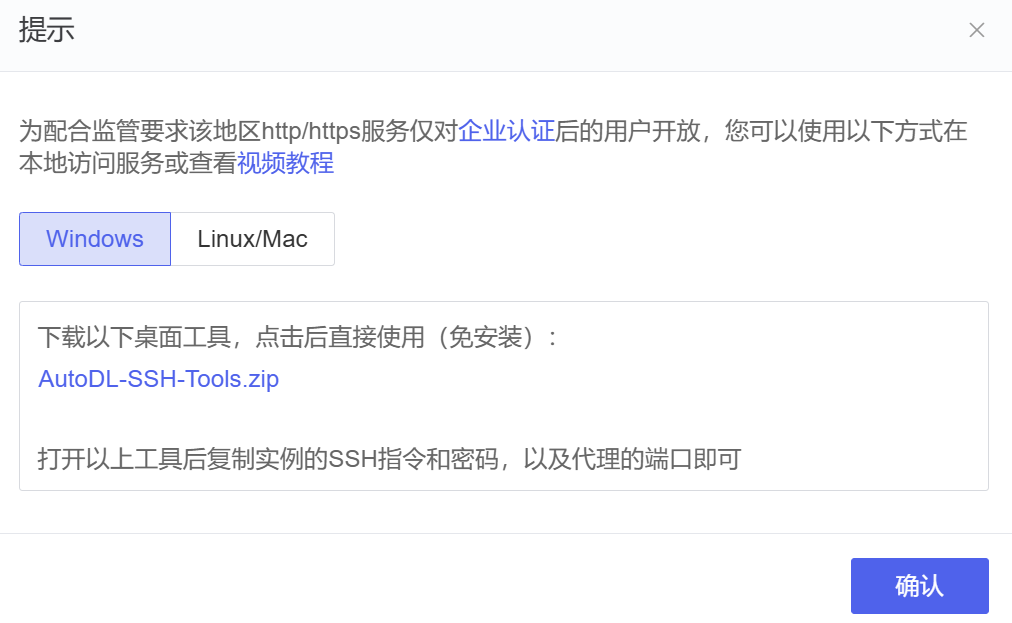
按照提示操作即可。
连接完成后,localhost的6006端口就能当作openai格式的chat/completion补全接口使用了!
启用简单的聊天界面
依次执行以下命令
git clone https://github.com/Anionex/QuickChat.git
cd QuickChat
pip install -r requirements.txt
# 启动之前需要先编辑.env文件
# .env 文件内容如下(不包含 ‘#’)
# OPENAI_API_KEY=132455
# OPENAI_API_BASE=http://127.0.0.1:6006/v1
python app.py
可能遇到的问题及解决方案
- 显存不足:
- 降低 --gpu-memory-utilization值
- 模型已经是INT4量化版本,显存占用相对较小
- 模型下载失败:
- 确保网络连接稳定
- 可以直接从ModelScope网站手动下载后解压到指定目录
- 确保下载目录有足够的写入权限
- 启动服务失败:
- 检查CUDA版本是否与PyTorch兼容
- 确保所有依赖都正确安装
- 检查端口6006是否被占用,如被占用可更换其他端口
参考资料
使用vLLM部署DeepSeek R1-Distill-Qwen-32B (Linux)
http://localhost:8080/archives/autodl-DeepSeek%20R1-Distill-Qwen-32B%20%28Linux%29