强化学习学习笔记
63
强化学习学习笔记
- Q-learning
场景:
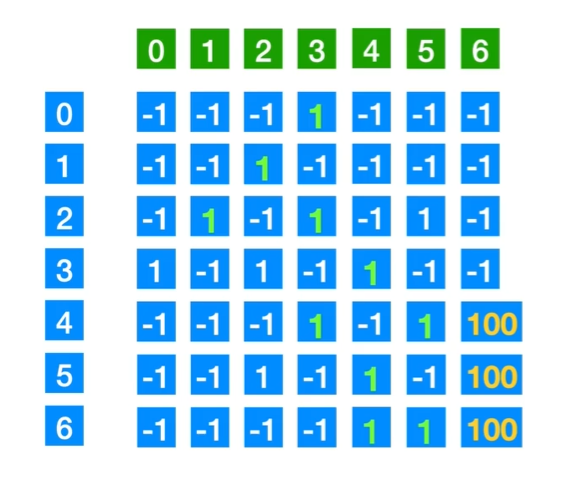
有一个迷宫,由很多节点组成。每个节点代表一个位置,节点之间有通道连接。我们想知道当我们站在一个指定的节点k时,往哪一个节点走是最佳的。假设我们要训练一个动物走迷宫,走错惩罚它,靠近终点就奖励它。
因为我们一开始不知道是否走某部是否靠近了终点,我们可以先不管那么多
考虑构造一个r矩阵,标识从i走到j的奖励,-1标识不能走,1表示能走,至于100,就是标记到了终点。
思路:
求一个函数Q(s, a)表示s状态选择a动作的期望累计奖励值,很显然答案是在s节点的时候往能使Q最大的方向走。怎么求Q(s,a)?求出Q的解析式吗?
Q-learning并不是这么做的,它的解决方案是“Q表”,在这个迷宫游戏中,Q表的i行j列代表了Q(s, a)的值,用“列表法”来表示函数
那如何求出最终的Q表?
一开始Q表是一个零矩阵
我们考虑现在状态为s(节点s),随机采取一个action a(往a走)
状态转移方程是
Q(s, a) \leftarrow Q(s, a) + \alpha \left( r + \gamma \max_{a'} Q(s', a') - Q(s, a) \right)关于这个公式的推导和更多内容,请参考强化学习的数学基础学习笔记
只要递归更新就行。
实际实现中,我们不用递归,而是用循环更新很多轮来替代,这种算法是?
因为只要轮数足够多,就可以传递信息到任何一个地方。
总结:Q-learning是一种机器学习算法,核心目标是找到一个最优策略,使得智能体在每个状态下都能选择一个动作,从而最大化未来的累计奖励。具体来说,Q-learning希望解决的问题是:在一个给定的环境中,智能体应如何行动,以便在**长期**内获得最大的回报。从Q-learning到DQN
在前面的例子中,我们的探险家在一个简单的迷宫中使用Q表记录每个房间的Q值。然而,当迷宫变得像BreakOut游戏一样复杂时,Q表变得庞大而不可管理。为了在这个复杂的环境中找到宝藏,我们需要一种更聪明的方法来记录和计算Q值。这时,深度Q网络(DQN)出现了。
qdn的核心想法是用一个模型来逼近Q函数的对应关系。
DQN算法流程
1. 初始化
- 初始化Q网络:随机初始化Q网络的参数(权重)。
- 初始化目标网络:复制Q网络的参数到目标网络(Target Network)。
- 初始化回放缓冲区:创建一个回放缓冲区(Replay Buffer)以存储经验样本和相关信息(包括TD误差和目标Q值)。
- 设置超参数:设置折扣因子\gamma、学习率、ε-贪心策略的参数(初始探索率ε和衰减率)、回放缓冲区大小、批量大小(Batch Size)等。
2. 交互和存储经验
- 重置环境:重置环境到初始状态。
- 选择动作:根据当前策略(例如ε-贪心策略)选择一个动作 a:
- 以概率ε选择一个随机动作(探索)。
- 以概率$1 - ε$选择当前Q网络中Q值最大的动作(利用)。
- 执行动作:在环境中执行选择的动作 a,观察即时奖励 r 和下一个状态 s'。
- 计算目标Q值:
- 使用目标网络计算目标Q值:
y = r + \gamma \max_{a'} Q'(s', a')- 计算当前Q值:
- 使用当前Q网络计算当前Q值 Q(s, a)。
- 计算TD误差:
- 计算TD误差 δ:
δ = y - Q(s, a)- 存储经验:将经验 (s, a, r, s', δ, y) 存储到回放缓冲区中,δ和y也一起存储,以便后续使用。
3. 更新Q网络
- 检查缓冲区大小:如果回放缓冲区中的样本数量达到一定阈值,开始训练。
- 优先抽样(优先经验回放):
根据存储的TD误差,优先抽取TD误差较大的样本进行训练。
TD误差就是简单的线性差值
抽取TD误差较大的样本的策略叫做优先经验回放策略 Prioritized Experience Replay
Prioritized Experience Replay(优先经验回放)是对标准经验回放的一种改进,旨在提高强化学习中样本利用的效率,从而加速学习过程。标准经验回放通过随机抽样来打破样本之间的时间相关性,优先经验回放则进一步通过优先抽取重要样本来加速学习。
优先经验回放的作用
1. 加速收敛:通过优先选择具有高TD误差的样本进行训练,可以更快地减少这些误差,从而加速学习过程。因为TD误差大的样本通常是策略和实际结果之间差异较大的样本,对模型的改进作用更显著。
2. 提高样本效率:优先经验回放可以更有效地利用有限的样本,提高训练的效率。与随机抽样相比,优先抽取重要样本可以更好地优化模型参数。
3. 改进策略评估:通过更频繁地更新误差较大的样本,可以更快地评估和改进策略,使得策略在复杂环境中表现更优。- 计算损失:
- 使用预先存储的目标Q值 y 和当前Q网络的Q值 Q(s, a),计算损失:
\text{Loss} = (Q(s, a) - y)^2- 反向传播和更新网络参数:
- 通过反向传播算法更新Q网络的参数。
- 更新目标网络:
- 周期性地将Q网络的参数复制到目标网络中。
4. 调整探索率
- 调整ε值:逐步减少探索率ε,以便逐渐从探索过渡到利用。
5. 重复训练
- 重复步骤2至4:在整个训练过程中,反复执行步骤2到4,直到达到预定的训练步数或收敛条件。
6. 推理
- 利用训练好的Q网络进行推理:
- 在训练完成后,固定Q网络的参数,不再更新。
- 使用训练好的Q网络,根据状态s选择Q值最大的动作 a 进行推理和决策。